ofstream的使用方法
ofstream的使用方法似乎以前在一篇文章里面看到过,今天拿出来复习一下吧 ofstream是从内存到硬盘,ifstream是从硬盘到内存,其实所谓的流缓冲就是内存空间;
在C++中,有一个stream这个类,任何的I/O都以这个“流”类为基础的,包括我们要认识的文档I/O,stream这个类有两个重要的运算符:
1、插入器(<<)
向流输出数据。比如说系统有一个默认的标准输出流(cout),一般情况下就是指的显示器,所以,cout<</"Write Stdout/"<<’//n’;就表示把字符串/"Write Stdout/"和换行字符(’//n’)输出到标准输出流。
2、析取器(>>)
从流中输入数据。比如说系统有一个默认的标准输入流(cin),一般情况下就是指的键盘,所以,cin>>x;就表示从标准输入流中读取一个指定类型(即变量x的类型)的数据。
在C++中,对文档的操作是通过stream的子类fstream(file stream)来实现的,所以,要用这种方式操作文档,就必须加入头文档fstream.h。下面就把此类的文档操作过程一一道来。
一、打开文档
在fstream类中,有一个成员函数open(),就是用来打开文档的,其原型是:
void open(const char* filename,int mode,int access);
参数:
filename: 要打开的文档名
mode: 要打开文档的方式
access: 打开文档的属性
打开文档的方式在类ios(是任何流式I/O类的基类)中定义,常用的值如下:
ios::app: 以追加的方式打开文档
ios::ate: 文档打开后定位到文档尾,ios:app就包含有此属性
ios::binary: 以二进制方式打开文档,缺省的方式是文本方式。两种方式的区分见前文
ios::in: 文档以输入方式打开(文档数据输入到内存)
ios::out: 文档以输出方式打开(内存数据输出到文档)
ios::nocreate: 不建立文档,所以文档不存在时打开失败
ios::noreplace:不覆盖文档,所以打开文档时假如文档存在失败
ios::trunc: 假如文档存在,把文档长度设为0
能够用“或”把以上属性连接起来,如ios::out|ios::binary
打开文档的属性取值是:
0:普通文档,打开访问
1:只读文档
2:隐含文档
4:系统文档
能够用“或”或“+”把以上属性连接起来,如3或1|2就是以只读和隐含属性打开文档。
例如:以二进制输入方式打开文档c://config.sys
fstream file1;
file1.open(/"c:////config.sys/",ios::binary|ios::in,0);
假如open函数只有文档名一个参数,则是以读/写普通文档打开,即:
file1.open(/"c:////config.sys/"); <=> file1.open(/"c:////config.sys/",ios::in|ios::out,0);
另外,fstream更有和open()相同的构造函数,对于上例,在定义的时侯就能够打开文档了:
fstream file1(/"c:////config.sys/");
特别提出的是,fstream有两个子类:ifstream(input file stream)和ofstream(outpu file stream),ifstream默认以输入方式打开文档,而ofstream默认以输出方式打开文档。 [Page]
ifstream file2(/"c:////pdos.def/");//以输入方式打开文档
ofstream file3(/"c:////x.123/");//以输出方式打开文档
所以,在实际应用中,根据需要的不同,选择不同的类来定义:假如想以输入方式打开,就用ifstream来定义;假如想以输出方式打开,就用ofstream来定义;假如想以输入/输出方式来打开,就用fstream来定义。
二、关闭文档
打开的文档使用完成后一定要关闭,fstream提供了成员函数close()来完成此操作,如:file1.close();就把file1相连的文档关闭。
三、读写文档
读写文档分为文本文档和二进制文档的读取,对于文本文档的读取比较简单,用插入器和析取器就能够了;而对于二进制的读取就要复杂些,下要就周详的介绍这两种方式
1、文本文档的读写
文本文档的读写很简单:用插入器(<<)向文档输出;用析取器(>>)从文档输入。假设file1是以输入方式打开,file2以输出打开。示例如下:
file2<</"I Love You/";//向文档写入字符串/"I Love You/"
int i;
file1>>i;//从文档输入一个整数值。
这种方式更有一种简单的格式化能力,比如能够指定输出为16进制等等,具体的格式有以下一些
操纵符 功能 输入/输出
dec 格式化为十进制数值数据 输入和输出
endl 输出一个换行符并刷新此流 输出
ends 输出一个空字符 输出
hex 格式化为十六进制数值数据 输入和输出
oct 格式化为八进制数值数据 输入和输出
setpxecision(int p) 配置浮点数的精度位数 输出
比如要把123当作十六进制输出:file1<<hex<<123;要把3.1415926以5位精度输出:file1<<setpxecision(5)<<3.1415926。
2、二进制文档的读写
①put()
put()函数向流写入一个字符,其原型是ofstream &put(char ch),使用也比较简单,如file1.put(’c’);就是向流写一个字符’c’。
②get()
get()函数比较灵活,有3种常用的重载形式:
一种就是和put()对应的形式:ifstream &get(char &ch);功能是从流中读取一个字符,结果保存在引用ch中,假如到文档尾,返回空字符。如file2.get(x);表示从文档中读取一个字符,并把读取的字符保存在x中。
另一种重载形式的原型是: int get();这种形式是从流中返回一个字符,假如到达文档尾,返回EOF,如x=file2.get();和上例功能是相同的。
更有一种形式的原型是:ifstream &get(char *buf,int num,char delim=’//n’);这种形式把字符读入由 buf 指向的数组,直到读入了 num 个字符或碰到了由 delim 指定的字符,假如没使用 delim 这个参数,将使用缺省值换行符’//n’。例如:
[NextPage]
file2.get(str1,127,’A’); //从文档中读取字符到字符串str1,当碰到字符’A’或读取了127个字符时终止。
③读写数据块
要读写二进制数据块,使用成员函数read()和write()成员函数,他们原型如下: [Page]
read(unsigned char *buf,int num);
write(const unsigned char *buf,int num);
read()从文档中读取 num 个字符到 buf 指向的缓存中,假如在还未读入 num 个字符时就到了文档尾,能够用成员函数 int gcount();来取得实际读取的字符数;而 write() 从buf 指向的缓存写 num 个字符到文档中,值得注意的是缓存的类型是 unsigned char *,有时可能需要类型转换。
例:
unsigned char str1[]=/"I Love You/";
int n;
ifstream in(/"xxx.xxx/");
ofstream out(/"yyy.yyy/");
out.write(str1,strlen(str1));//把字符串str1全部写到yyy.yyy中
in.read((unsigned char*)n,sizeof(n));//从xxx.xxx中读取指定个整数,注意类型转换
in.close();out.close();
四、检测EOF
成员函数eof()用来检测是否到达文档尾,假如到达文档尾返回非0值,否则返回0。原型是int eof();
例: if(in.eof()) ShowMessage(/"已到达文档尾!/");
五、文档定位
和C的文档操作方式不同的是,C++ I/O系统管理两个和一个文档相联系的指针。一个是读指针,他说明输入操作在文档中的位置;另一个是写指针,他下次写操作的位置。每次执行输入或输出时,相应的指针自动变化。所以,C++的文档定位分为读位置和写位置的定位,对应的成员函数是seekg()和seekp()。seekg()是配置读位置,seekp是配置写位置。他们最通用的形式如下:
istream &seekg(streamoff offset,seek_dir origin);
ostream &seekp(streamoff offset,seek_dir origin);
streamoff定义于 iostream.h 中,定义有偏移量 offset 所能取得的最大值,seek_dir 表示移动的基准位置,是个有以下值的枚举:
ios::beg: 文档开头
ios::cur: 文档当前位置
ios::end: 文档结尾
这两个函数一般用于二进制文档,因为文本文档会因为系统对字符的解释而可能和预想的值不同。例:
file1.seekg(1234,ios::cur); //把文档的读指针从当前位置向后移1234个字节
file2.seekp(1234,ios::beg); //把文档的写指针从文档开头向后移1234个字节
fstream的用法
开一个文档
fstream f;
f.open(/"1.txt/", ios::in | ios::binary);
if (!f.is_open()) // 检查文档是否成功打开
cout << /"cannot open file./" << endl;
ios::in和ios::bianry均为int型,定义文档打开的方式。
ios::in -- 打开文档用于读。
ios::out -- 打开文档用于写,假如文档不存在,则新建一个;存在则清空其内容。
ios::binary -- 以二进制bit流方式进行读写,默认是ios::text,但最好指定这种读写方式,即使要读写的是文本。因为在ios::text模式下,在写入时’// n’字符将转换成两个字符:回车+换行(HEX: 0D 0A) 写入,读入时作逆转换,这容易引起不必要的麻烦。 [Page]
ios::app -- 打开文档在文档尾进行写入,即使使用了seekp改变了写入位置,仍将在文档尾写入。
ios::ate -- 打开文档在文档尾进行写入,但seekp有效。
读写位置的改变
f.seekg(0, ios::beg); // 改变读入位置 g mean Get
f.seekp(0, ios::end); // 改变写入位置 p mean Put
第一个参数是偏移量offset(long),第二个参数是offset相对的位置,三个值:
ios::beg -- 文档头 ios::end -- 文档尾 ios::cur -- 当前位置
文档读写
char s[50];
f.read(s, 49);
s[50] = ’//0’; // 注意要自己加上字符串结束符
char *s = /"hello/";
f.write(s, strlen(s));
补充 记得读写完成后用f.close()关闭文档。
例子 下面的程式用于删除带有行号的源程式中的行号。
#include <iostream>
#include <fstream>
using namespace std;
//定义要删除的行号格式,下面定义的是型如: #0001 的行号
const int LINE_NUM_LENGTH = 5;
const char LINE_NUM_START = ’#’;
int main(int argc, char *argv[])
{
fstream f;
char *s = NULL;
int n;
for (int i = 1; i < argc; i++) {
cout << /"Processing file /" << argv[i] << /"....../";
f.open(argv[i], ios::in | ios::binary);
if (!f.is_open()){
cout << /"CANNOT OPEN/"<< endl;
continue;
}
f.seekg(0, ios::end);
[NextPage]
n = f.tellg(); // 文档大小
s = new char[n+1];
f.seekg(0, ios::beg);
f.read(s, n);
s[n] = ’//0’;
f.close();
// 采用一种简单的判断,碰到LINE_NUM_START后接一个数字,
// 则认为他是个行号.
for (int j = 0; j < n; j++) {
if (s[j] == LINE_NUM_START && [Page]
(s[j+1] >= ’0’ && s[j+1] <= ’9’)) {
for (int k = j; k < j + LINE_NUM_LENGTH; k++)
s[k] = ’ ’;
}
}
f.open(argv[i], ios::out | ios::binary);
if (!f.is_open()) {
cout << /"CANNOT OPEN/" << endl;
delete[] s;
continue;
}
f.write(s, n);
f.close();
cout << /"OK/" << endl;
delete[] s;
}
return 0;
}
hdu2389Rain on your Parade
//做啦好久老是WA,不知到为什么,刚刚开始吧他们都设成是双浮点型,老是过不了;改成整形就过啦;
//后来又是超时,吧cin改成scanf();果断过!!!!!
#include<stdio.h>
#include<queue>
#include<iostream>
#include<string.h>
#include<math.h>
using namespace std;
#define eps 1e-6
const int MAXN=3005;
const int INF=1<<28;
int g[MAXN][MAXN],Mx[MAXN],My[MAXN],Nx,Ny;int dx[MAXN],dy[MAXN],dis;
bool vst[MAXN];
struct Node1{
int x,y,s;
}guests[MAXN];
struct Node2{
int x,y;
}um[MAXN];
double distance(Node1 a,Node2 b){
double x=a.x-b.x;
double y=a.y-b.y;
return sqrt(x*x+y*y);
}
bool searchP(void){
queue<int> Q;
dis = INF;
memset(dx, -1, sizeof(dx));
memset(dy, -1, sizeof(dy));
for (int i = 0; i < Nx; i++)
if (Mx[i] == -1){
Q.push(i); dx[i] = 0;
}
while (!Q.empty()) {
int u = Q.front(); Q.pop();
if (dx[u] > dis) break;
for (int v = 0; v < Ny; v++)
if (g[u][v] && dy[v] == -1) {
dy[v] = dx[u]+1;
if (My[v] == -1) dis = dy[v];
else{
dx[My[v]] = dy[v]+1;
Q.push(My[v]);
}
}
}
return dis != INF;
}
bool DFS(int u){
for (int v = 0; v < Ny; v++)
if (!vst[v] && g[u][v] && dy[v] == dx[u]+1) {
vst[v] = 1;
if (My[v] != -1 && dy[v] == dis) continue;
if (My[v] == -1 || DFS(My[v])) {
My[v] = u; Mx[u] = v;
return 1;
}
}
return 0;
}
int MaxMatch(void){
int res = 0;
memset(Mx, -1, sizeof(Mx));
memset(My, -1, sizeof(My));
while (searchP()) {
memset(vst, 0, sizeof(vst));
for (int i = 0; i < Nx; i++)
if (Mx[i] == -1 && DFS(i)) res++;
}
return res;
}
int main(){
//freopen("test.in","r",stdin);
//freopen("test.out","w",stdout);
int n,m,t,i,j;
int T,iCase=0;
scanf("%d",&T);
while(T--)
{
iCase++;
scanf("%d",&t);
scanf("%d",&m);
for(i=0;i<m;i++)
scanf("%d%d%d",&guests[i].x,&guests[i].y,&guests[i].s);
scanf("%d",&n);
for(i=0;i<n;i++)
scanf("%d%d",&um[i].x,&um[i].y);
Nx=m;Ny=n;
memset(g,0,sizeof(g));
for(i=0;i<m;i++)
{
for(j=0;j<n;j++)
{
if(distance(guests[i],um[j])/guests[i].s-t<eps)
{
g[i][j]=1;
}
}
}
printf("Scenario #%d:\n%d\n\n",iCase,MaxMatch());
}
return 0;
}
hdu 1429胜利大逃亡(续)
//hash判重
//好孩子;
//hdu1429利用二进制的&和|运算:
#include<iostream>
#include<queue>
using namespace std;
const int T = 22;
char g[T][T];
int vis[T][T][1030],n,m,t,ans;
int dir[4][2]={0,1,1,0,0,-1,-1,0};
struct point{
int x;
int y;
int step;
int key;
};
point s;
void inset(){
for(int i=0;i<n;i++){
cin>>g[i];
for(int j=0;j<m;j++){
if(g[i][j]=='@'){
s.x=i;
s.y=j;
s.key=0;
s.step=0;
}
}
}
}
void bfs(){
queue<point> Q;
point tp;
ans=-1;
memset(vis,0,sizeof(vis));
vis[s.x][s.y][s.key]=1;
Q.push(s);
while(!Q.empty()){
tp=Q.front();Q.pop();
for(int k=0;k<4;k++){
s=tp;
s.x=tp.x+dir[k][0];
s.y=tp.y+dir[k][1];
if(s.x>=0 && s.x<n && s.y>=0 && s.y<m && g[s.x][s.y]!='*' && !vis[s.x][s.y][s.key]){
if(g[s.x][s.y]=='.' || g[s.x][s.y]=='@'){
vis[s.x][s.y][s.key]=1;
s.step+=1;
Q.push(s);
//cout<<s.x<<" "<<s.y<<endl;
}
if(g[s.x][s.y]=='^'){
if(s.step+1<t) ans=s.step+1;
return ;
}
if(g[s.x][s.y]>='A' && g[s.x][s.y]<='J'){
int key=1<<(g[s.x][s.y]-'A');
if(s.key & key){
vis[s.x][s.y][s.key]=1;
s.step+=1;
Q.push(s);
//cout<<s.x<<" "<<s.y<<endl;
}
}
if(g[s.x][s.y]>='a' && g[s.x][s.y]<='j'){
int key=1<<(g[s.x][s.y]-'a');
if(!vis[s.x][s.y][s.key|key]){
vis[s.x][s.y][s.key|key]=1;
s.step+=1;s.key=s.key|key;
Q.push(s);
//cout<<s.x<<" "<<s.y<<endl;
}
}
}
}
}
}
int main(){
while(cin>>n>>m>>t){
inset();
bfs();
cout<<ans<<endl;
}
return 0;
}
hdu 3336 Count the string
//hdu 3336
//Answer 好孩子
//刚刚思想是采用KMP+DP的递推;前1—next[i]与后面next[i]—i-1刚刚好相等
//这个就在前面的基础上加一代表前i-1个为前最的最大重复数;
//思路是next[]数组总体往后移一位;
就像:abcdabcd;
next[]:
-1 0 0 0 0 1 1 1 1
后移一位:
0 0 0 0 1 1 1 1
刚刚好对应字符下表看成是1开始的每一位:
//状态方程:cont[i]=cont[next[i]]+1;
//本题就是把所有的cont[]加起来;
#include<iostream>
using namespace std;
const int T=300000;
const int size=10007;
int next[T],cont[T],len;
char a[T];
void getnext(){
int i,j;
next[0]=-1;i=0;j=-1;
while(i<len){
if(j==-1 || a[i]==a[j]){
i++;
j++;
next[i]=j;
}
else j=next[j];
}
}
//dp
int Gram(){
int i,sum=0;
memset(cont,0,sizeof(cont));
for(i=1;i<=len;i++){
cont[i]=(cont[next[i]]+1)%size; //前缀i的相等加一;
sum=(sum+cont[i])%size;
}
return sum;
}
int main(){
int R;
freopen("in.txt","r",stdin);
freopen("out.txt","w",stdout);
cin>>R;while(R--){
cin>>len;
cin>>a;
getnext();
int sum=Gram();
cout<<sum<<endl;
}
return 0;
}
算法
KM 算法:
二分图匹配匈牙利算法(邻接表矩阵实现
#include <iostream>
#include <cstdio>
using namespace std;
int const MAXN = 250;
int graph[MAXN][MAXN], cnt[MAXN];
//邻接表矩阵,点度
bool ck[MAXN];//记录是否被访问
int match[MAXN];//匹配数组,记录右端到左端的匹配
int V, E;//点数、边数
bool search(int G[][MAXN], int k)
{//找增广边
}
int hungary(int G[][MAXN], int left)
{//传入矩阵和左端点数,传出匹配的对数
}
Hopcroft-Carp的算法
/********************************************** 二分图匹配(Hopcroft-Carp的算法)。 初始化:g[][]邻接矩阵 调用:res=MaxMatch(); Nx,Ny要初始化!!! 时间复杂大为 O(V^0.5 E) 适用于数据较大的二分匹配 ***********************************************/ const int MAXN=3001; const int INF=1<<28; int g[MAXN][MAXN],Mx[MAXN],My[MAXN],Nx,Ny; int dx[MAXN],dy[MAXN],dis; bool vst[MAXN]; bool searchP() { queue<int>Q; dis=INF; memset(dx,-1,sizeof(dx)); memset(dy,-1,sizeof(dy)); for(int i=0;i<Nx;i++) if(Mx[i]==-1) { Q.push(i); dx[i]=0; } while(!Q.empty()) { int u=Q.front(); Q.pop(); if(dx[u]>dis) break; for(int v=0;v<Ny;v++) if(g[u][v]&&dy[v]==-1) { dy[v]=dx[u]+1; if(My[v]==-1) dis=dy[v]; else { dx[My[v]]=dy[v]+1; Q.push(My[v]); } } } return dis!=INF; } bool DFS(int u) { for(int v=0;v<Ny;v++) if(!vst[v]&&g[u][v]&&dy[v]==dx[u]+1) { vst[v]=1; if(My[v]!=-1&&dy[v]==dis) continue; if(My[v]==-1||DFS(My[v])) { My[v]=u; Mx[u]=v; return 1; } } return 0; } int MaxMatch() { int res=0; memset(Mx,-1,sizeof(Mx)); memset(My,-1,sizeof(My)); while(searchP()) { memset(vst,0,sizeof(vst)); for(int i=0;i<Nx;i++) if(Mx[i]==-1&&DFS(i)) res++; } return res; }
关于图论中一些名称的介绍
关于图论中一些名称的介绍:
独立集:
独立集是指图的顶点集的一个子集,该子集的导出子图不含边.如果一个独立集不是任何一个独立集的子集, 那么称这个独立集是一个极大独立集.一个图中包含顶点数目最多的独立集称为最大独立集。最大独立集一定是极大独立集,但是极大独立集不一定是最大的独立集。
支配集:
与独立集相对应的就是支配集,支配集也是图顶点集的一个子集,设S 是图G 的一个支配集,则对于图中的任意一个顶点u,要么属于集合s, 要么与s 中的顶点相邻。 在s中除去任何元素后s不再是支配集,则支配集s是极小支配集。称G的所有支配集中顶点个数最 少的支配集为最小支配集,最小支配集中的顶点个数成为支配数。
最小点的覆盖:
最小点的覆盖也是图的顶点集的一个子集,如果我们选中一个点,则称这个点将以他为端点的所有边都覆盖了。将图中所有的边都覆盖所用顶点数最少,这个集合就是最小的点的覆盖。
最大团:
图G的顶点的子集,设D是最大团,则D中任意两点相邻。若u,v是最大团,则u,v有边相连,其补图u,v没有边相连,所以图G的最大团=其补图的最大独立集。
一些性质:
最大独立集+最小覆盖集=V
最大团=补图的最大独立集
最小覆盖集=最大匹配
树状数组
问题提出:已知数组a[],元素个数为n,现在更改a中的元素,要求得新的a数组中i到j区间内的和(1<=i<=j<=n).
思考:对于这个问题,我们可以暴力地来解决,从a[i]一直累加到a[j],最坏的情况下复杂度为O(n),对于m次change&querry,合起来的复杂度为O(m*n),在n或m很大的情况下,这样的复杂度是让人无法忍受的.另外,如果没有元素的变更,我们完全可以存储sum[1,k](k=1,2,……),然后对任意给定的查找区间[i,j],都可以方便的用ans=sum[1,j]-sum[1,i-1],当然这只是没有元素改变的情况下的比较优化的解法.那么对于有元素变更的问题是否有更高效的方法呢?(废话!没有我还写啥?!)可以想一下,每次更改的元素是比较少的,有时候甚至每次只改变一个元素,但是在用暴力方法求区间和的时候,却对区间内所有的元素都累加了一遍,这样其实造成了许多无谓的运算.这时候也许会想到如果能把一些结果存起来会不会减少很多运算?答案是肯定的,但问题是怎么存,存什么?如果存任意区间的话,n比较大的时候不但内存吃不消,而且存储的量太大,不易更改,反而得不偿失;那么也许可以考虑存储特定的一些区间(比如说线段树,其实现在讨论的问题用线段树完全可以解,以后再详细写线段树).那么现在重新回过头来,看下这个问题,我们已经确定了要存储一些特定区间sum的想法,接下来我们要解决的无非是两个问题:1、减少更改元素后对这些区间里的sum值的更改时间.2、减少查找的时间.
好了废话了这么半天,无非是想让自己以及看到的人明白为什么要用树状数组.
接下来正式入题.
首先我们可以借鉴元素不变更问题的优化方法,先得到前i-1项之和and前j项之和,以s[i]表示前i项之和,那么sum[i,j]=s[j]-s[i-1].那么现在的问题已经转化为求前i项之和了.另外,我们已经确定要存储一些特定区间的和,现在就要来揭示这些特定的区间究竟指什么.
在文字说明之前先引入一个非常经典的,在网上找到的树状数组文章里几乎都要出现的一个图片
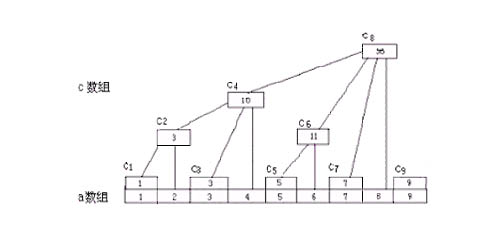
从图中不难发现,c[k]存储的实际上是从k开始向前数k的二进制表示中右边第一个1所代表的数字个元素的和(这么说可能有点拗口,令lowbit为k的二进制表示中右边第一个1所代表的数字,然后c[k]里存的就是从a[k]开始向前数lowbit个元素之和)这么存有什么好处呢?无论是树状数组还是线段树,都用到了分块的思想,而树状数组采用这样的存储结构我想最主要的还是这样方便计算,我们可以用位运算轻松地算出lowbit.分析一下这样做的复杂度:对于更改元素来说,如果第i个元素被修改了,因为我们最终还是要求和,所以可以直接在c数组里面进行相应的更改,如图中的例子,假设更改的元素是a[2],那么它影响到得c数组中的元素只有c[2],c[4],c[8],我们只需一层一层往上修改就可以了,这个过程的最坏的复杂度也不过O(logN);对于查找来说,如查找s[k],只需查找k的二进制表示中1的个数次就能得到最终结果,比如查找s[7],7的二进制表示中有3个1,也就是要查找3次,到底是不是呢,我们来看上图,s[7]=c[7]+c[6]+c[4],可能你还不知道怎么实现这个过程.
还以7为例,二进制为0111,右边第一个1出现在第0位上,也就是说要从a[7]开始向前数1个元素(只有a[7]),即c[7];
然后将这个1舍掉,得到6,二进制表示为0110,右边第一个1出现在第1位上,也就是说要从a[6]开始向前数2个元素(a[6],a[5]),即c[6];
然后舍掉用过的1,得到4,二进制表示为0100,右边第一个1出现在第2位上,也就是说要从a[4]开始向前数4个元素(a[4],a[3],a[2],a[1]),即c[4].
代码实现:
 int lowbit(int x)//计算lowbit
int lowbit(int x)//计算lowbit {
{

 return x&(-x);
return x&(-x); }void add(int i,int val)//将第i个元素更改为val{ while(i<=n)
}void add(int i,int val)//将第i个元素更改为val{ while(i<=n) {
{ c[i]+=val; i+=lowbit(i);
c[i]+=val; i+=lowbit(i); }}int sum(int i)//求前i项和{ int s=0; while(i>0) { s+=c[i]; i-=lowbit(i); } return s;}
}}int sum(int i)//求前i项和{ int s=0; while(i>0) { s+=c[i]; i-=lowbit(i); } return s;}
#include <cstdio> |
002 |
#include <cstdlib> |
003 |
#include <string> |
004 |
#include <iostream> |
005 |
#define NO 0; |
006 |
using namespace std; |
007 |
struct data |
008 |
{ |
009 |
int l,r,mid,num; |
010 |
data *lc,*rc; |
011 |
}; |
012 |
|
013 |
|
014 |
data *create(int l,int r) |
015 |
{ |
016 |
data *head=(data *)malloc(sizeof(data)); |
017 |
head->l=l;head->r=r;head->mid=(l+r)/2; |
018 |
head->num=NO; |
019 |
if(r-l==1) |
020 |
{ |
021 |
head->lc=NULL; |
022 |
head->rc=NULL; |
023 |
} |
024 |
else |
025 |
{ |
026 |
head->lc=create(l,head->mid); |
027 |
head->rc=create(head->mid,r); |
028 |
} |
029 |
return head; |
030 |
} |
031 |
|
032 |
|
033 |
void add(data *head,int num,int l) |
034 |
{ |
035 |
if(head->l==l && head->r==l+1) |
036 |
{ |
037 |
head->num+=num; |
038 |
return; |
039 |
} |
040 |
else |
041 |
{ |
042 |
head->num+=num; |
043 |
if(l<head->mid) |
044 |
add(head->lc,num,l); |
045 |
else |
046 |
add(head->rc,num,l); |
047 |
} |
048 |
} |
049 |
|
050 |
|
051 |
int get(data *head,int l,int r) |
052 |
{ |
053 |
if(head->l==l && head->r==r) |
054 |
{return head->num;} |
055 |
else |
056 |
{ |
057 |
if(l>=head->mid) |
058 |
return get(head->rc,l,r); |
059 |
else if(r<=head->mid) |
060 |
return get(head->lc,l,r); |
061 |
else |
062 |
{ |
063 |
int a=get(head->lc,l,head->mid); |
064 |
int b=get(head->rc,head->mid,r); |
065 |
return a+b; |
066 |
} |
067 |
} |
068 |
} |
069 |
|
070 |
void clear(data *head) |
071 |
{ |
072 |
if(head==NULL) |
073 |
return; |
074 |
else |
075 |
{ |
076 |
clear(head->lc); |
077 |
clear(head->rc); |
078 |
free(head); |
079 |
} |
080 |
} |
081 |
int main() |
082 |
{ |
083 |
int t=0,T,NUM,i,num,a,b; |
084 |
data *head; |
085 |
string s; |
086 |
scanf("%d",&T); |
087 |
while(T--) |
088 |
{ |
089 |
t++; |
090 |
printf("Case %d:\n",t); |
091 |
scanf("%d",&NUM); |
092 |
head=create(0,NUM); |
093 |
for(i=0;i<NUM;++i) |
094 |
{ |
095 |
scanf("%d",&num); |
096 |
add(head,num,i); |
097 |
} |
098 |
while(cin>>s && s!="End") |
099 |
{ |
100 |
scanf("%d%d",&a,&b); |
101 |
if(s=="Add") |
102 |
{ |
103 |
add(head,b,a-1); |
104 |
} |
105 |
else if(s=="Sub") |
106 |
{ |
107 |
add(head,-b,a-1); |
108 |
} |
109 |
else |
110 |
{ |
111 |
printf("%d\n",get(head,a-1,b)); |
112 |
} |
113 |
} |
114 |
clear(head); |
115 |
} |
116 |
return 0; |
117 |
} |
KMP
字符串匹配算法:KMP学习心得
这周的数据结构课讲的是串,本以为老师会讲解KMP算法的,谁知到他直接略过了...没办法只能自己研究,这一琢磨就是3天,期间我都有点怀疑自己的智商...不过还好昨天半夜终于想明白了个中缘由,总结一些我认为有助于理解的关键点好了...
书上有的东西我就不说了,那些东西网上一搜一大片,我主要说一下我理解的由前缀函数生成的next数组的含义,先贴出求next数组的方法。
当一个字符串以0为起始下标时,next[i]可以描述为"不为自身的最大首尾重复子串长度"。
也就是说,从模式串T[0...i-1]的第一个字符开始截取一段长度为m(m < i-1)子串,再截取模式串T[0...i-1]的最后m个字符作为子串,如果这两个子串相等,则该串就是一个首尾重复子串。我们的目的就是要找出这个最大的m值。
例如:

若 i = 4 ,则 i - 1 = 3 , m = next[4] = 2
从T[0...3]截取长度为2的子串,为"ab"
从T[0..3]截取最后2个字符,为"ab"
此时2个子串相等,则说明 next[4] = 2 成立,也可证明 m = 2 为最大的m值。
本来一开始我是没有加"不为自身"这个限制条件的,可是后来我发现一种情况:

若 i = 4 ,则 i - 1 = 3 , m = next[4] = 3
从T[0...3]截取长度为3的子串,为"aaa"
从T[0..3]截取最后3个字符,为"aaa"
此时2个子串相等,则说明 next[4] = 3 成立。
但是我发现如果next[4] = 4:
从T[0...3]截取长度为4的子串,为"aaaa"
从T[0..3]截取最后4个字符,为"aaaa"
此时2个子串也是相等的,那么是不是说明 next[4] 应该等于4呢?
仔细观察后发现,如果 next[4] = 4 ,那么T[0...3]的前4个字符和后4个字符是重合的,并且重复子串和T[0...3]也是相等的。看过教材后发现教材中给出的前缀函数定义有一句为:next[j] = max{k | 0 < k < j 且 'p[0]...p[k-1]' = 'p[j-k+1]...p[j-1]'},应该不包含子串为本身的情况...
这样再做PKU 2406 和 PKU 1961 的时候就很简单了,用 length - next[length] 求出"不为自身的最大首尾重复子串长度",此时需要多求一位next[length]值(而next[length]刚好反映了lenght之前不为。。的长度),若最大重复子串的长度是length的非1整数倍,则证明字符串具有周期重复性质。
PKU 2752 是求 前缀 == 后缀的长度,也就是首尾重复子串长度,利用next数组记录的"不为自身的最大首尾重复子串长度"可以马上得到结果。
#include<iostream>
using namespace std;
int a[1000010],b[10010],next[10010];
int lena,lenb;
void inset()
{
int i;
scanf("%d%d",&lena,&lenb);
for(i=0;i<lena;i++)
scanf("%d",&a[i]);
for(i=0;i<lenb;i++)
scanf("%d",&b[i]);
}
void Gurm()
{
int j=0,k=-1;
next[0]=-1;
while(j<lenb)
{
if(k==-1 || b[j]==b[k])
{
++j;
++k;
next[j]=k;
}
else
{
k=next[k];
}
}
}
int kmp()
{
int i=0,j=0;
Gurm();
while(i<lena && j<lenb)
{
if(j==-1 || a[i]==b[j] )
{
i++;
j++;
}
else
{
j=next[j];
}
}
if(j<lenb) return -1;
else return i-j+1;
}
int main()
{
//freopen("D:\\in.txt","r",stdin);
int R;scanf("%d",&R);
while(R--)
{
inset();
printf("%d\n",kmp());
}
return 0;
}
KMP:next[]的应用。
* 一般next[i]与优化next[i]的区别:
*如果模式串p下标为i的字符(字符第一个的下标为0)的前k个字符与开头前k个字符相等(0=<k<i 注意这里没有等于i)
* 对于一般的next[i],不管p[i]是否等于p[k+1],next[i]都是等于k;
* 对于优化后的next[i],如果p[i]不等于p[k+1],则next[i]=k,反之,next[i]=0.
* 这题的next[]是从0求到n,有n+1个值,因此对于next[i]=k的意义(0除外)就为:字符串下标为i的前k-1个字符与字符串头k个字符相等(上面提到的next[i]是与前k个字符与头k个字符相等next[i]才等于k)。
* 对于长度为i个字符串,i-next[i](满足i % (i-next[i])==0)代表的意义就是 长度为i的字符串 的 最小循环子串的长度
* 因此 字符串中存在周期的子串的最大循环次数=i/ (i-next[i]);
*